How We Evaluate New AI Models for AI Dungeon
Many of you have reached out to ask if we’ll be implementing the new models that OpenAI announced yesterday. To help answer that, we decided to share this blog post we’ve been working on to explain our process of evaluating new AI models for AI Dungeon.
Since the early days of Large Language Models (LLMs), we’ve worked hard to use the most advanced models in the world for AI Dungeon. We’ve seen incredible advances in the power of these models, especially in the past 6 months. We’d like to share more about how we think about AI Models at AI Dungeon, including the entire lifecycle of selection, evaluation, deployment, and retirement. This should answer some questions we’ve seen in the community about the decisions we make and what you can expect from models in AI Dungeon in the future.
Large Language Models + AI Dungeon: A History Lesson
AI Dungeon was born when our founder, Nick Walton, saw the launch of OpenAI’s GPT2 model and wondered if it could become a dynamic storyteller (just like in Dungeons and Dragons).
Spoiler: it worked! 🎉
A hackathon prototype turned into an infinite AI-powered game unlike anything before. From the very first few days, the cost of running an AI-powered game became readily apparent. The first version of AI Dungeon cost $10,000/day to run (so much that the university hosting the first version had to shut it down after 3 days!). Thus began our constant quest to identify and implement affordable and capable AI models so that anyone could play AI Dungeon.
The first public version of AI Dungeon (in December 2019) was powered by GPT-2. Later, we switched to using GPT-3 through OpenAI (in 2020). While it was exciting to be using the state-of-the-art AI tech at that time, unlike today, there were essentially no other competitive AI models, commercial or open source. We couldn’t just switch models if issues arose (and they certainly did). When you asked us for cheaper options or unlimited play, we didn’t have the leverage to advocate for lower costs for you since there was no competition creating price pressure.
But that was all about to change. New open-source and commercial models entered the market, and we explored them as they became available. The open-source GPT-J (summer of 2021) and GPT-NeoX were promising, and AI21’s Jurassic models (Fall of 2021) were explored over the next few years. Fast-forward to today, there are hundreds of models and model variants. AI Dungeon is uniquely positioned to leverage new advances in AI from various providers at scale.
Given the number of available models, picking which models to check out can be tricky. Evaluating and deploying models takes time. Here are some of the ways we think about this process:
Our Strategy for AI Models
We’ve made a few choices that impact how we handle AI model work in AI Dungeon. Together, these allow us to give you the best role-play experience we can.
- Model Agnostic. We’ve chosen to be model agnostic so you have access to the best models on the market and benefit from the billions of dollars currently being invested into better models by multiple companies. You’ve seen the fruit of this strategy lately with the launch of MythoMax, Tie Fighter, Mixtral 7x8B, GPT-4-Turbo, Llama 3 70B, and WizardLM 8x22B. Read more →
- Vendor Agnostic. We’ve also chosen to be vendor agnostic so you benefit from the competition among current providers. The recent doubling in context length was possible because of this. Read more →
- Operate Profitably. Given the scale of AI Dungeon, we could bankrupt the company very easily if we weren’t careful. We spend a lot of time thinking about AI cost to ensure AI Dungeon will be around for a long time. Our goal is to give as much as possible to you without putting the future of AI Dungeon at risk.
- Iterate Quickly. We’ve designed our technology, team, and models around fast learning and iteration. The recent rise of instruction-based models means models can be quickly adapted to the AI Dungeon experience without needing to create (or wait for) a fine-tuned model suited for role-play adventures.
- Enable endless play. We want to offer models that allow you to play how you want. Outside of a few edge cases (such as sexual content involving minors and guidelines for publicly published content shared with our community), we want you to go on epic adventures, slay dragons, and explore worlds without constraint. Because of our model/vendor agnostic strategy, we have the flexibility to ensure we get to control the approach. Read more about this strategy in our blog post about the Walls Approach →
How We Identify New Models to Evaluate
At first, we evaluated every model that launched. Early providers included OpenAI, Cohere, AI21, and Eleuther. Lately, we haven’t been able to keep up with the rate of new models being launched. Here’s one visualization of just how the AI Model space has accelerated.
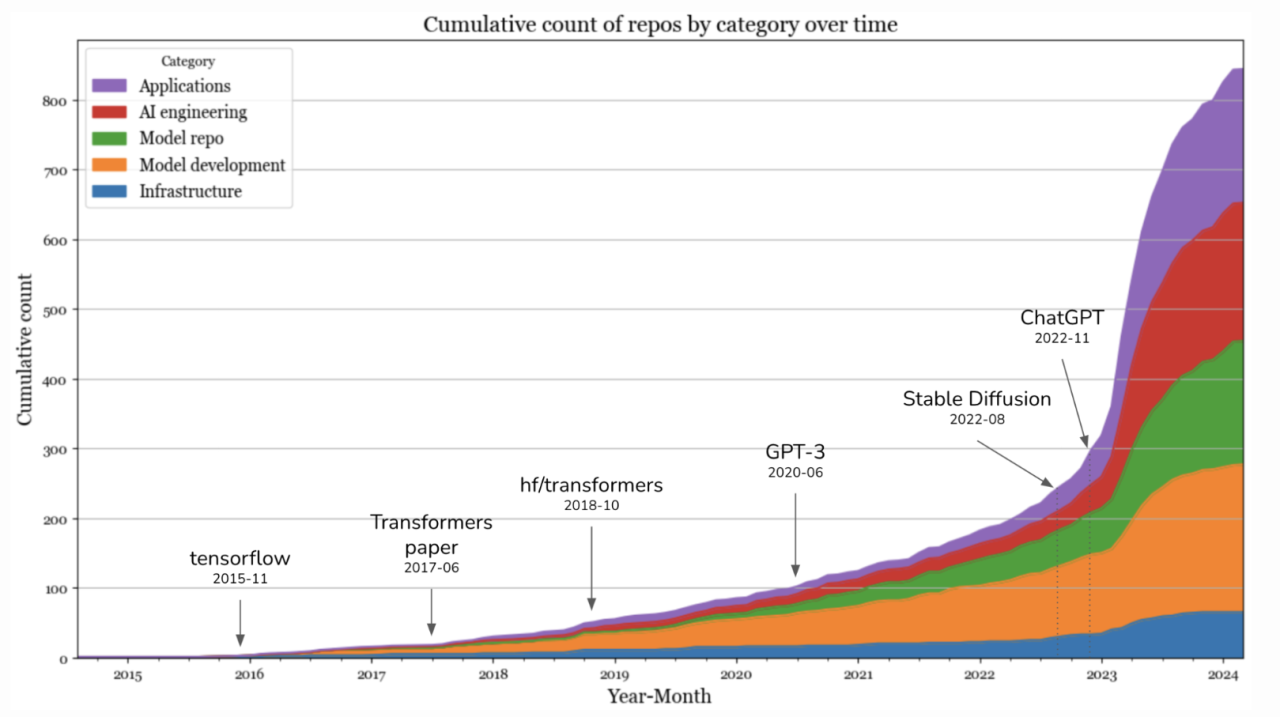
We’re selective about which models to evaluate. We base that decision on information we source from the AI community on X, LLM leaderboards, our technology partners, and members of our AI Dungeon community.
When a model piques our interest and seems like it could be worth exploring (when it could have a desirable combo of cost/latency/quality/etc), we do some light exploration around feasibility and desirability. If there’s a playground where we can test the model, we’ll play around a bit ourselves to see what we think. We also talk to our current providers to see how/when they may offer a model at scale.
If everything seems positive, we move into our model evaluation process.
How We Evaluate AI Models
Once we’ve identified a model we are interested in, then the real evaluation starts. Here are the steps we take to verify if a model is worth offering to you in AI Dungeon:
- Research. As mentioned in the selection process, we look to a number of sources, including industry benchmarks, leaderboards and discussion in the broader AI community, for indicators of which models are the most promising.
- Playground testing. Someone on our team experiments to confirm we think it could work with AI Dungeon.
- Finetuning (if required). GPT-J (which powers Griffin) and AI21 Mid (which powers Dragon) are examples of models that clearly needed fine-tuning to perform well for AI Dungeon. Newer models have been able to perform well without finetuning.
- Integrate the model into AI Dungeon and make sure it works. For example, we recently evaluated a model (Smaug) that seemed compelling on paper but wasn’t able to generate coherent outputs due to its inability to handle the action/response format we use in AI Dungeon.
- Internal testing. Does the model behave as we expect it to with AI Dungeon’s systems? For instance, when we first implemented ChatGPT, it became clear that we’d need additional safety systems to minimize the impact of the model’s moralizing behavior.
- Alpha testing. Our community alpha testers help us find issues and give a qualitative sense of how good the model is. The models from Google didn’t make it past our Alpha testers due to moralizing and lower quality writing than competing models.
- AI Comparison. Players who opt into the “Improve the AI” setting are occasionally presented with two AI outputs and asked to select the best one. These outputs are from two different models, and we compare how often one model’s responses are preferred over another’s. To achieve statistical significance for the test, we collect a few thousand responses per AI Comparison.
- Experimental access. The final step is giving you all access to the new models in an experimental phase. We often make significant adjustments to how we handle models as a result of the feedback you share. In some cases, models may not be promoted past the experimental phase if players aren’t finding value from them. For instance, we’re considering whether to promote Llama 3 70B since players have reported it repeats frequently.
At any step of the process, we may decide to stop evaluation. Most models don’t make it through our evaluation process to become an offered model on AI Dungeon.
How We Deploy Models
Once we commit to offering a model on AI Dungeon, we then figure out the best way to run it at scale. With private models we often can only run them with the creator of the model (like AI21’s models). For open-source models, we can choose between running on rented hardware or using other providers that run LLMs as a service (which is our preference). By optimizing our model deployment costs we’re able to deliver better AI to users for the same price.
We also have an alert system and series of dashboards that show us the number of requests, average context in and out, latency profiling (average request time, max request time), and estimated cost. This lets us keep our AI models running smoothly and quickly respond to any issues that come up.
How We Retire Models
Given the complexity of models, it’s sometimes necessary to retire models that are no longer adding much value to the community. While it would be nice to offer every AI model perpetually, maintaining models takes time and development resources away from other improvements on AI Dungeon, including new AI models and systems.
Because of that, we need to balance the value a model provides against the cost of maintaining it (especially in developer time). We’re guessing most of you are no longer pining for the good old days of GPT-2 😉.
Before deciding to retire a model, we consider usage, tech advances (i.e., instruction-based models), latency, uptime, stability, error rates, costs, player feedback, and the general state of models in AI Dungeon (i.e., how many do we have for each tier).
Each model is unique, like an ice cream flavor. Taking away your favorite flavor can be frustrating, especially if that model does things that other models don’t (like mid-sentence completion). We hope there’s solace in the fact that when models are retired, the recovered development resources are reinvested into better models and new features that make AI Dungeon a better experience for you.
Today here’s the % breakdown of model usage for various models:
Free Players
MythoMax 73%
TieFighter 17.8%
Mixtral 8.8%
Griffin 0.4%
Subscribers
Mixtral 79%
MythoMax 8%
WizardLM 8x22B 5%
TieFighter 4%
Llama 3 70B 2%
Dragon 1%
GPT-4-Turbo 0.5%
ChatGPT 0.4%
Griffin 0.01%
You’ll notice a few things. MythoMax is our most popular model, even capturing some use from paid players who have access to all the models. Mixtral is the clear favorite for premium players.
Because of the advances in tech as well as low usage, we will be retiring Griffin, Dragon, and ChatGPT models on May 31st, 2024. Griffin, while it’s served us well, has exceptionally low usage, the worst uptime of all our models, and a high rate of errors. It requires more developer maintenance than all other models we offer. Dragon and ChatGPT also have lower usage now. Retiring models enables us to focus on other product work including additional model improvements, bug fixing, and building new features.
GPT-4-Turbo is somewhat of an outlier. Despite its moralizing, it’s one of the best story writing models available. Players who use it love it! While its usage rate is low relative to other models, it’s actually well represented for a model only available to Legend and Mythic tiers, though it’s clear players still favor Llama 3 70B and WizardLM 8x22B. We are evaluating the recently announced GPT-4o as a potential replacement for GPT-4 Turbo which could mean offering higher context lengths. Although venture-funded OpenAI says they’ll offer limited use of GPT-4o for free through their own ChatGPT client, it will not be a free model for API users (like AI Dungeon), so it will still be a premium model for us. First, though, it needs to pass the evaluations we’ve outlined above.
Moving Forward
This was a deeper peek into our approach to models than we’ve ever given. We hope it’s clear that we spend a lot of time thinking about which models we can offer to you and how to provide them best.
Thank you to all who have given feedback on our AI models. We will continue to communicate as much as we can about models and planned model improvements. It’s exciting to realize AI will only get better from here. The past few months have shown us just how fast things can change. And we’re excited to explore with you how much better role play can be as AI keeps improving.