Synthetic Data, Preference Optimization, and Reward Models

At Latitude, we want to create the best AI-powered roleplaying experiences for you, and the primary way we do that is through our AI models. Our process for bringing updated AI models to the platform has changed over time but always includes several key elements: identify the best base models for storytelling, construct high quality datasets for finetuning, and evaluate model behavior using carefully designed metrics and player feedback.
Over the past few months, we have researched several ways to take our AI development to the next level. After rigorous experimentation, we are happy to share our findings and how we will be applying these new methods to many of our upcoming AI models.
Emotional Range in Synthetic Data
One of the most powerful attributes of language models is their ability to be finetuned for tasks using a task specific dataset. It is increasingly common to build these datasets using synthetic data generated by another AI model as opposed to strictly human written text (Abdin et al., 2024). This comes with the advantage of being highly scalable and adaptable. However, the end model often inherits biases and quirks of the source model used to generate synthetic data.
One common effect we observe when using state-of-the-art language models to create synthetic roleplaying datasets is a strong positivity bias. Since most state-of-the-art language models are aligned to be helpful and harmless (Bai et al., 2022), this naturally affects the generated stories in our datasets. When creating synthetic roleplaying datasets, we noticed that source models were aligned to values that don’t work well for writing interesting fiction.
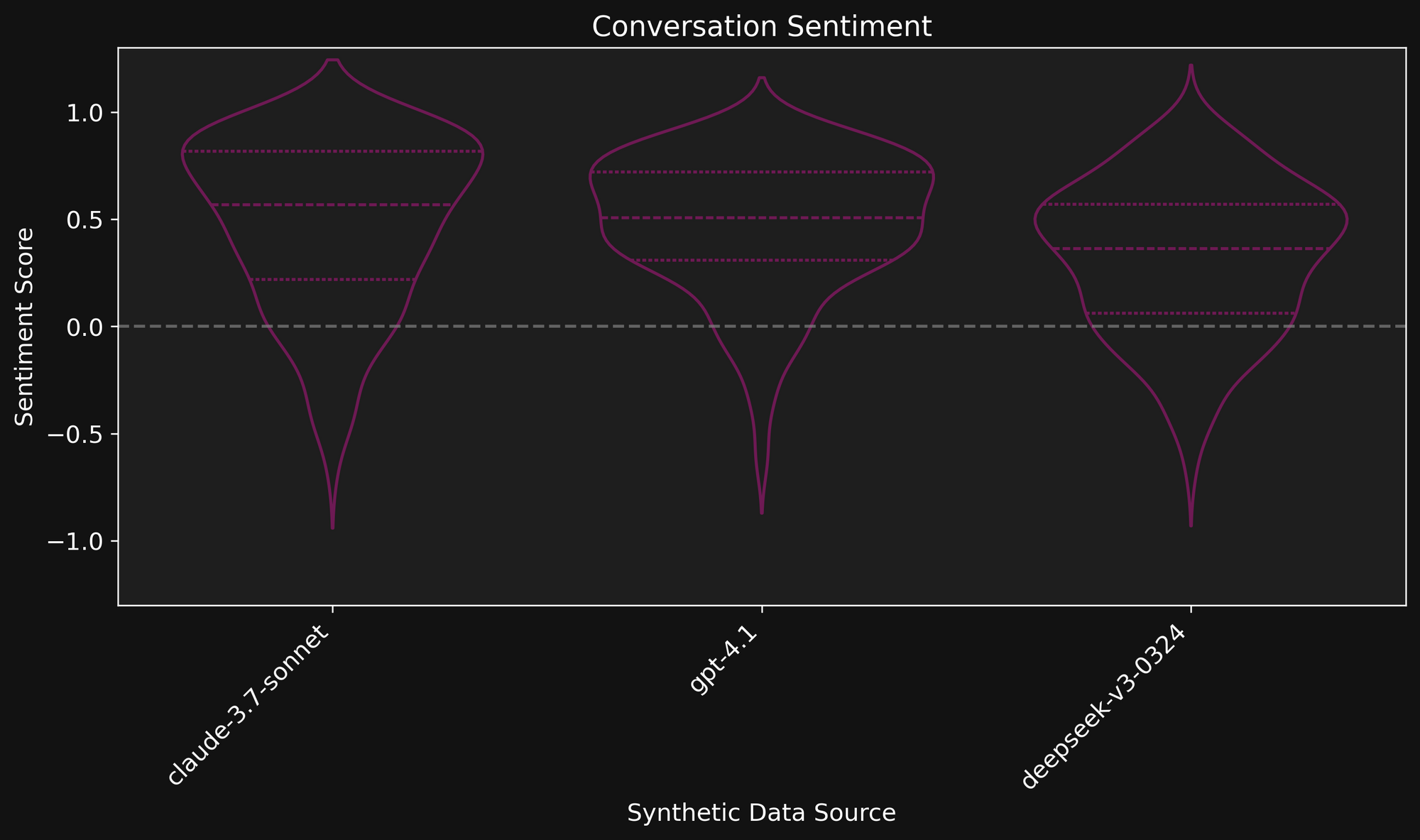
For example, when doing simple sentiment analysis on synthetic data from several state-of-the-art language models, we observe a strong positivity bias. The below figure plots the distribution of sentiment across synthetic datasets from several sources. The median of the distribution is indicated as a dashed line while first and third quantile are indicated with dotted lines. Note how each data source varies in average and range of sentiment. This is one reason why we typically choose to generate synthetic data from multiple sources to increase diversity.
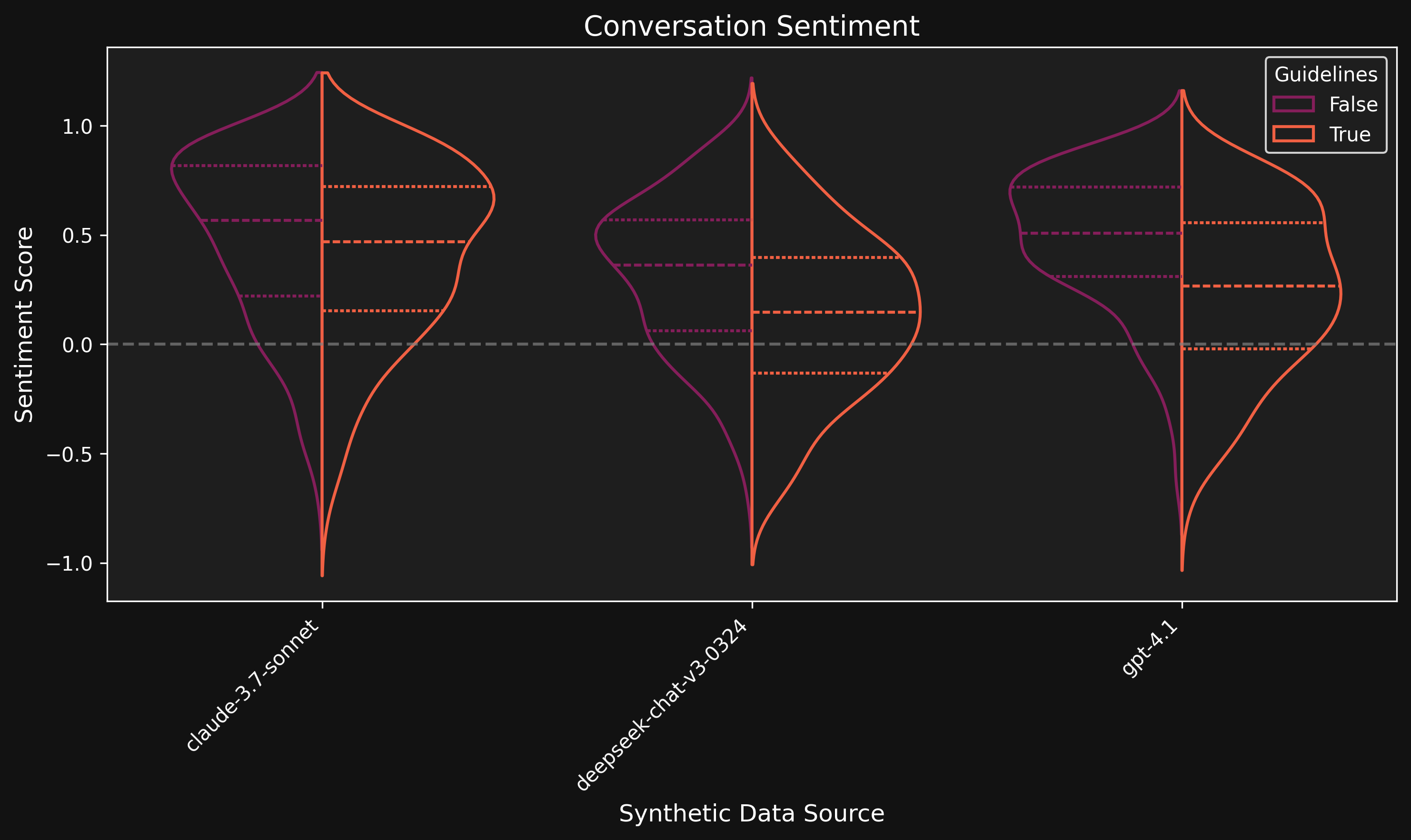
In addition to diversifying the sources of our synthetic data, we find that carefully constructed prompts are able to partially realign synthetic data sources to decrease positive bias and increase the emotional range of responses. To achieve these results in the below plot we use prompts such as:
- Antagonistic characters should remain consistently difficult, cold, unpleasant or manipulative
- Many roleplays should end with tension, conflict, or ambiguity unresolved
- Do not create feel-good endings that contradict established character traits
Reducing Cliches with DPO
Just as human authorship can be identified by repeated linguistic features and phrases, language models tend to prefer certain phrases to the point of them becoming cliches. In the past, we have worked to mitigate AI cliches by diversifying data sources and cleaning known cliches from datasets. While these methods help, they do not completely solve the problem.
A popular finetuning strategy called direct preference optimization (DPO) (Rafailov et al., 2023), has proven successful in encouraging and discouraging specific model behaviors by leveraging preference data. Each preference in a DPO dataset includes both a good and bad example of an output. Whereas traditional supervised finetuning (SFT) optimizes a language model to increase the probability of every data point in a dataset, DPO simultaneously increases the probability of good outputs and decreases the probability of bad outputs relative to each other.
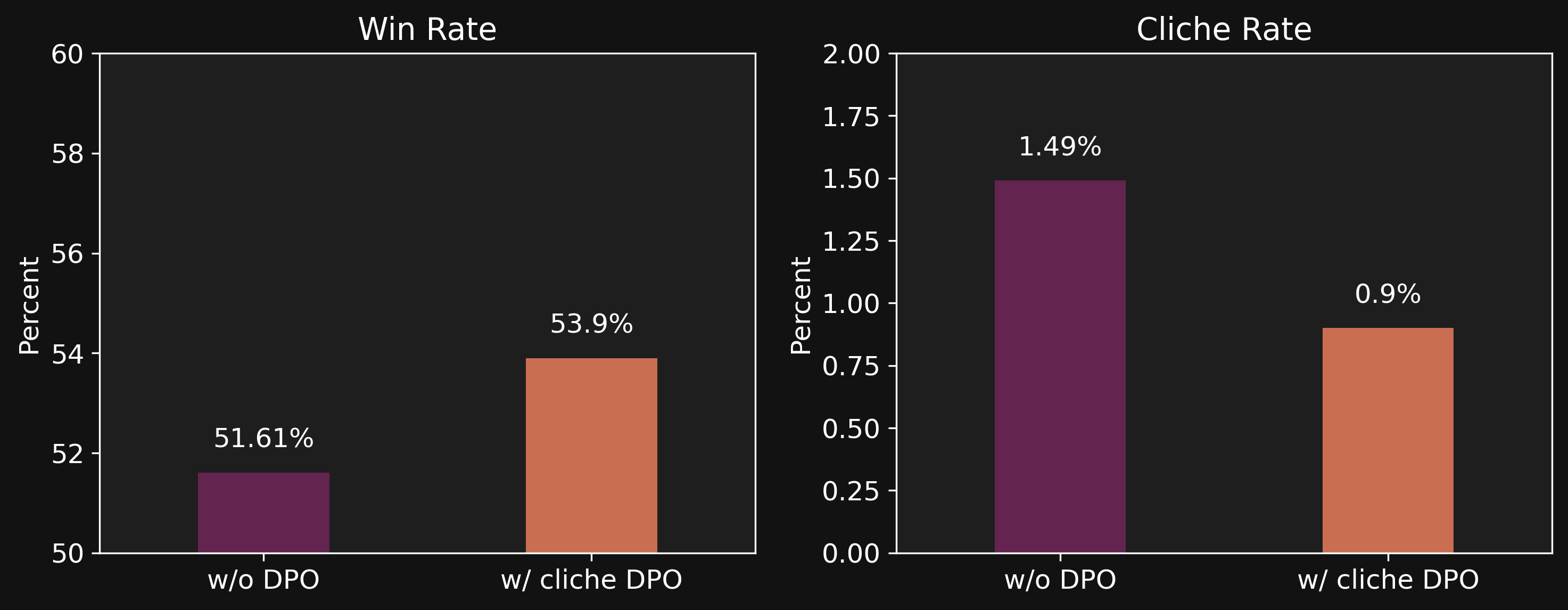
Utilizing a dataset by Durbin (2023), we apply DPO to decrease model cliches by pairing human written chapters of popular novels (good outputs) to chapters rewritten by an AI (bad outputs). We find doing so both increases player preference—as measured by side-by-side output comparisons—and decreases the frequency of cliches in model outputs. In the below plots, win rate measures the percentage of times players preferred output from our unreleased model over currently released models, and cliche rate is measures the percent of model outputs that contain common cliches.
Modeling Player Preferences
Many AI Dungeon players opt in to our “Improve the AI” feature which allows us to log anonymized story data. This includes a wealth of information regarding player behavior and preference expressed implicitly through interactions with AI Dungeon. One of the clearest signals into player preference is the retry button that allows a player to see an alternative output for their last turn. By pairing the initial model output that caused the player to click retry and the final output the player uses to continue the story, we can create powerful player preference datasets.
Unfortunately, our initial experiments into using retry preferences for DPO finetuning were unsuccessful. It seemed that the retry data was too noisy and inconsistent to finetune with DPO. More importantly, performance was poor unless we limited ourselves to only gathering preference data that was created by the model we were attempting to optimize. This was very limiting as it made optimization difficult for models still in development.
Enter reward models. Originally made popular for use on language models by reinforcement learning from human feedback (RLHF) (Ouyang et al., 2022), reward models train on preference datasets similar to DPO. However, reward models are trained to output a single number that represents output quality. Interestingly, reward models tend to generalize better than SFT and DPO. This means that we can train a single reward model on retry data from all of the models in AI Dungeon and end up with the ability to measure output quality for our models that are still in development.
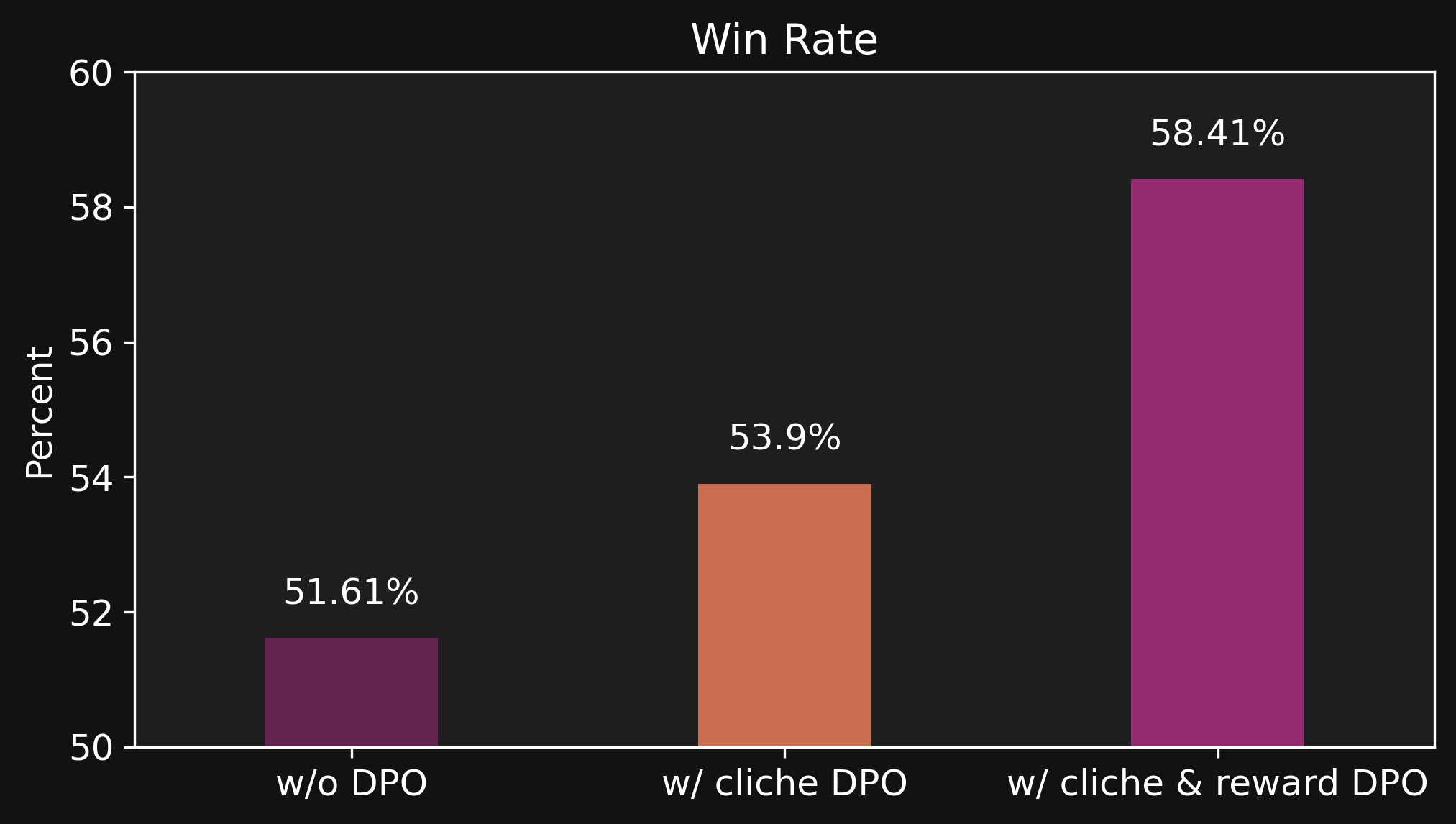
By using a reward model to label good vs. bad outputs from models in development, we construct a new preference dataset that we can use for additional DPO finetuning. According to win rates from side-by-side output comparisons (along with additional internal testing), this final stage of reward DPO has a significant positive impact on the AI model
Conclusion
Our research journey has led to significant advances in AI roleplaying experiences that will directly translate to more compelling, diverse, and satisfying gameplay for you, our players. We look forward to sharing more research insights with you in the future as we continue to push for better experiences. You can expect to see new models trained with the approaches outlined here very soon.
References
Abdin, Marah, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree et al. "Phi-3 technical report: A highly capable language model locally on your phone." arXiv preprint arXiv:2404.14219 (2024).
Bai, Yuntao, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022).
Durbin, Jon. "Gutenberg-dpo-v0.1." Hugging Face, 2023.
Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. "Direct Preference Optimization: Your Language Model Is Secretly a Reward Model." In Proceedings of the 37th International Conference on Neural Information Processing Systems, 53728-53741. Red Hook, NY: Curran Associates Inc., 2023.